Inputs, Outputs and Data Flow
Understanding how data flows between components is fundamental to building effective pipelines in TangleML. This guide explains the low-level mechanics of inputs, outputs, and data passing between tasks.
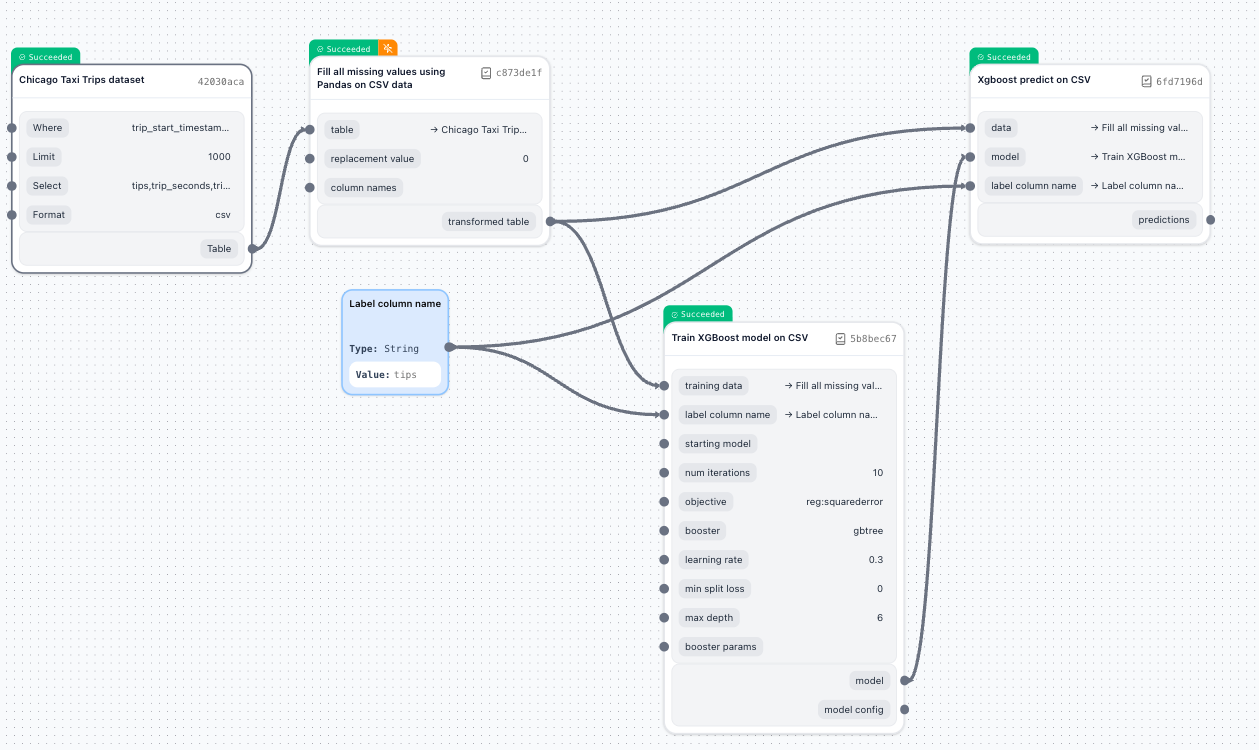
How data actually flows
Unlike systems like Airflow (Python classes) or Ray (Python functions), TangleML Components are command-line interface (CLI) programs. That means, that in a pipeline, every task can be executed on different machines, at different times. So passing objects, like in a regular function call, is not possible. Instead all inputs are converted to command line arguments and outputs are stored to files. Some input values may be safely passed as command line arguments, while other input values may need to be passed as file paths.
Not all data can be passed/received as a simple string. Examples: binary data, large data, directories. In all these cases, the code should read data from a file or directory pointed to by a path.
When components exchange data in TangleML:
- Producer component writes data to a local file path provided by TangleML as arguments to the command line invocation.
- System handles storage transparently (uploads to Google Cloud Storage, S3, etc.)
- Consumer component reads from a local file path provided by TangleML as arguments to the command line invocation.
- System handles retrieval transparently (mounts or downloads from storage)
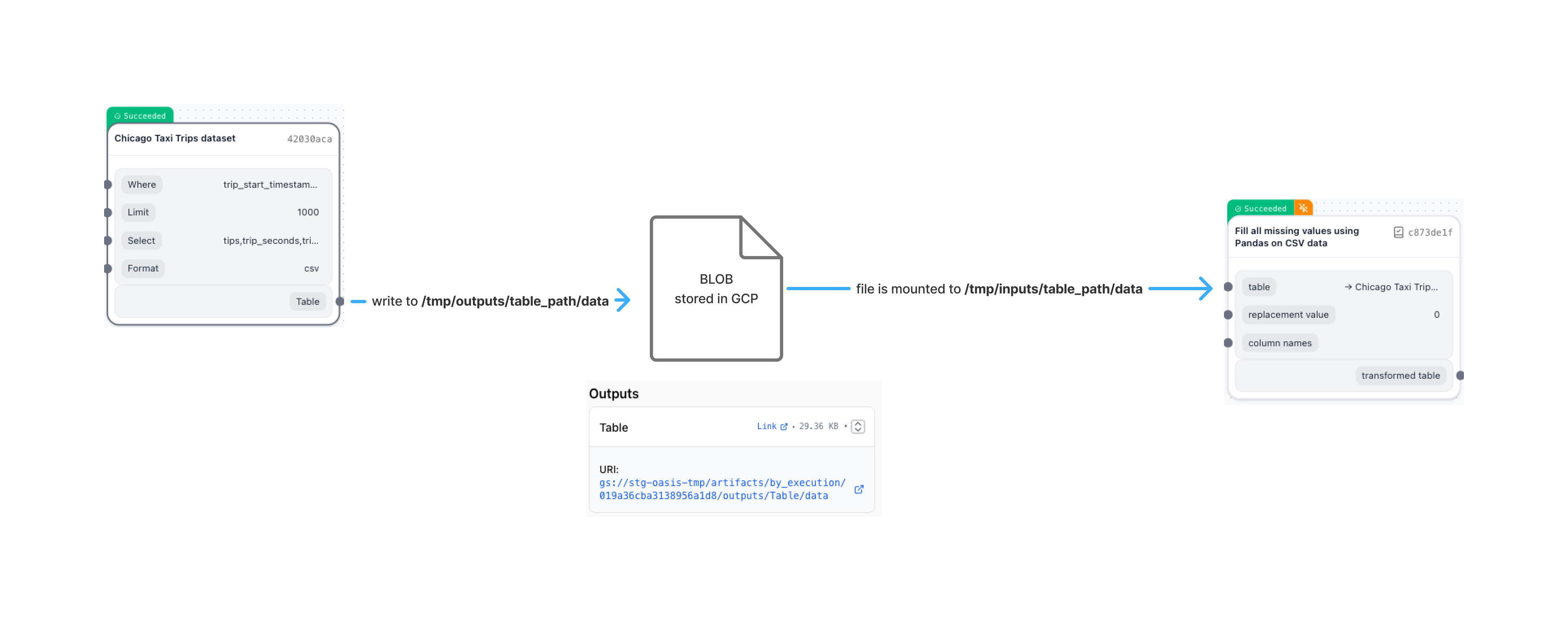
In TangleML, components always work with data using local file paths, so they never need to worry about where the data is actually stored. The underlying storage could be Google Cloud Storage, Amazon S3, or anything else - the details are completely hidden from the component code. Ideally, TangleML mounts input artifacts as read-only disks and connects output locations directly to the running container. This means a component simply reads and writes to local paths, and the system streams data straight to and from the global artifact storage. If mounting isn't possible, TangleML takes care of downloading the needed input files before starting the component and uploads any outputs afterward. No matter which approach is used, the component's code only ever sees and works with local files.
Components should never hardcode output paths. Always use the paths provided by TangleML through output placeholders.
- Python
- Shell
def filter_text(
text_path: InputPath(),
filtered_text_path: OutputPath(),
pattern: str,
):
import re
with open(text_path, 'r') as reader:
with open(filtered_text_path, 'w') as writer:
for line in reader:
if re.search(pattern, line):
writer.write(line)
ext_path=$0
pattern=$1
filtered_text_path=$2
mkdir -p "$(dirname "$filtered_text_path")"
grep "$pattern" < "$text_path" > "$filtered_text_path"
Input and output types
From the system's low-level perspective, there are no types; everything is treated as blobs or directories. Types in component specifications are primarily for human understanding and tooling (e.g., Python type checking, visual editors)
Inputs may be defined as InputValue or InputPath. InputValue is suitable for small values that can be passed as command line arguments. InputPath is suitable for large values that need to be passed as file paths.
Outputs are always defined as OutputPath.
:::tip Why no OutputValue? CLI programs don't have a standard way to return values. They can only write to files, directories, or stdout (which can be redirected to a file). :::
Unlike some systems (Vertex AI, KFP v2) that separate "parameters" (constants) from "artifacts" (connected data), TangleML has one unified input system.
# TangleML: Any input can receive any source
inputs:
- name: threshold
type: Float
# Can receive:
# - Constant: {value: 0.5}
# - Task output: {taskOutput: optimizer.best_threshold}
# - Graph input: {graphInput: user_threshold}
- name: data
type: Dataset
# Same flexibility for all inputs!
:::warning Systems with Separated Inputs In Vertex/KFP v2, you must decide at component creation whether an input is a "parameter" (constant only) or "artifact" (connection only). This causes friction when you need to change how data flows. :::
Unified inputs offer several practical advantages for users. They provide flexibility, allowing you to switch between hardcoded values and dynamic, data-driven ones without needing to change how your components are written. This simplifies experimentation, making it easy to run hyperparameter tuning or try out different configurations. Additionally, debugging becomes more convenient—you can quickly test components by substituting outputs with simple test constants as needed.
To convert inputs into a proper data types, components must parse input values or read input files with appropriate language-specific tools.
Type conversions and edge cases
What happens when you connect an Output to an incompatible Input? The launcher handles conversions automatically:
| Scenario | What Happens |
|---|---|
| Output → InputValue | Launcher downloads artifact, converts to string (if small enough) |
| Constant → InputPath | Launcher uploads value to staging area, provides path |
| Large artifact → InputValue | System error: "Artifact too big to consume as value" |
| Directory → InputValue | System error: Cannot convert directory to string |
When connecting an output to an InputValue input, the TangleML will attempt to read the content of the artifact and convert it to a string.
If the artifact is large, the launcher will return an error: Artifact is too big to consume as value. Consume it as file instead. input_name='Format'
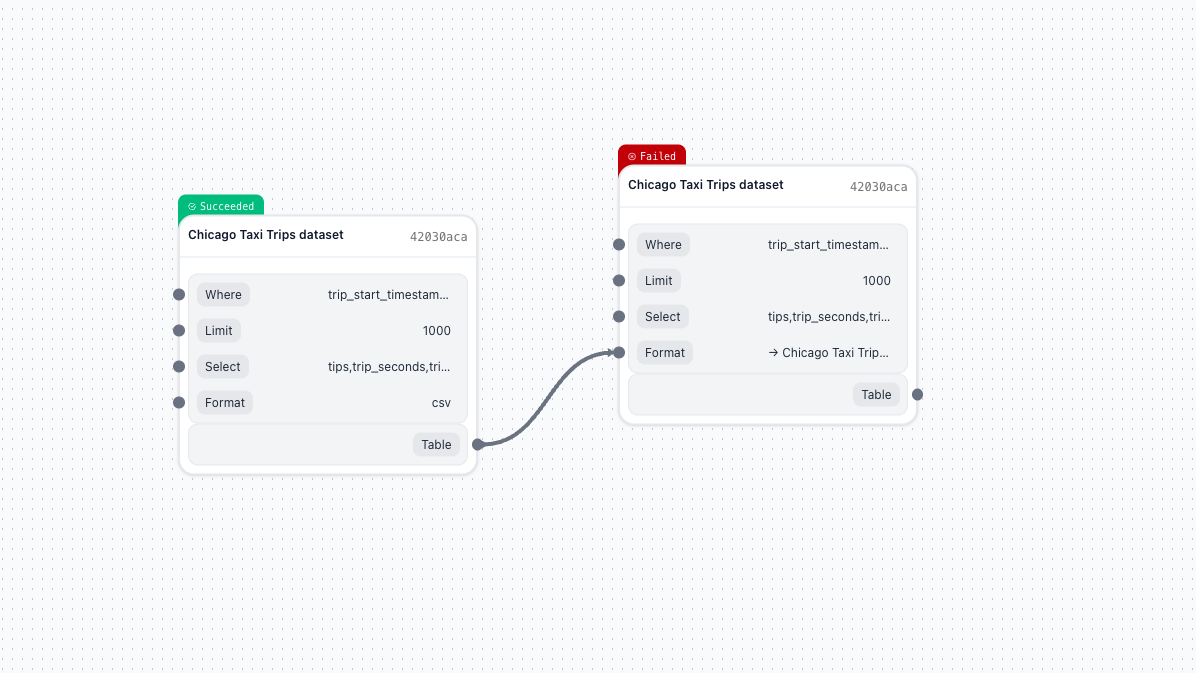
Troubleshooting data flow issues
Common errors and solutions
| Error | Cause | Solution |
|---|---|---|
| "Artifact too big to consume as value" | Output connected to InputValue, but data > threshold | Use InputPath instead or reduce data size |
| "Cannot convert directory to string" | Directory output connected to InputValue | Component must accept InputPath for directories |
| 404 on artifact URL | Artifact older than TTL (30 days) | Re-run pipeline or check metadata (size, hash still available) |
| "No such file or directory" | Hardcoded paths instead of placeholders | Use OutputPath placeholders: {OutputPath: model} |
Debugging data transfer
To debug data flow issues:
- Check artifact sizes in the UI - Large size changes indicate problems
- Verify artifact types - Ensure blob vs directory matches expectations
- Review launcher logs - Shows mounting/downloading operations
- Test locally first - Use local Docker to verify component I/O