Understanding Artifacts in TangleML
Artifacts are the data produced by components (read: any output), stored in TangleML's artifact storage system:
- Blobs: Nameless files (just data)
- Directories: Nameless containers with named files inside
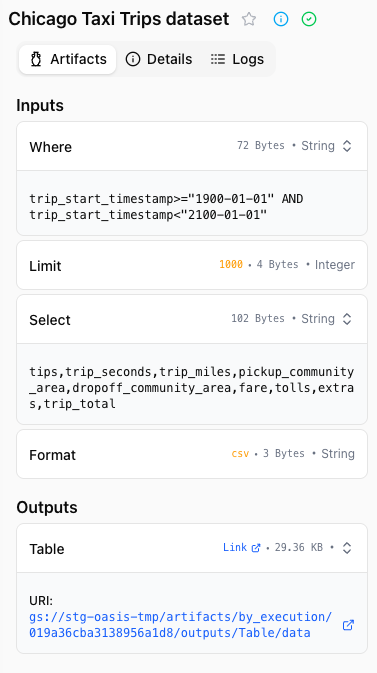
Artifacts can be accessed in the Pipeline Run page, in the Artifacts tab.
Small values may be stored in the TangleML database without putting any TTL on them.
Blob vs directory artifacts
Blob artifacts
Blobs are nameless data files. Components always write to and read from a file named data:
# Component writes blob
with open("/tmp/outputs/model/data", "wb") as f:
pickle.dump(model, f)
# Downstream component reads blob
with open("/tmp/inputs/model/data", "rb") as f:
model = pickle.load(f)
This naming convention ensures compatibility - no component expects specific filenames.
Directory artifacts
Directories are nameless containers, but files inside retain their names:
# component writes directory
output_dir = "/tmp/outputs/dataset/data/"
os.makedirs(output_dir, exist_ok=True)
pd.DataFrame(...).to_parquet(f"{output_dir}/train.parquet")
pd.DataFrame(...).to_parquet(f"{output_dir}/test.parquet")
# Downstream component reads directory
input_dir = "/tmp/inputs/dataset/data/"
train = pd.read_parquet(f"{input_dir}/train.parquet")
test = pd.read_parquet(f"{input_dir}/test.parquet")
Artifact attributes
Every artifact has:
- Size: Total bytes (for directories, cumulative size)
- Hash: MD5 (Google Cloud) or SHA-256 (local) for content-based caching
- Is Directory: Boolean flag
- URL: Storage location (hidden from components, managed by system)
Storage and retention
| Artifact Type | Storage Duration | What's Retained After TTL |
|---|---|---|
| Large artifacts | 30 days (Shopify) | Metadata only (size, hash) |
| Small values | Permanent | Full value in database |
The retention period for large artifacts is configured per deployment. When a retention period is configured, the run view displays an Artifact Storage warning at the top of the artifact section reminding you that artifacts older than the retention period may no longer be available in remote storage. The notice includes the configured number of days. If your deployment does not configure a retention period, this notice is suppressed.
When artifacts are no longer available
Artifacts may become unavailable after their retention period has elapsed, or because of a transient storage error. When the inline viewer cannot load an artifact, an inline notice replaces the preview:
- Artifact unavailable — the artifact could not be found in storage (HTTP 404). When a retention period is configured, the notice mentions that the artifact may have expired and includes the retention window.
- Failed to load artifact — an unexpected error occurred while fetching the artifact. The HTTP status code and message are included to help diagnose the issue.
Artifact metadata such as size and hash remains visible even when the underlying data is no longer available.
Inline artifact viewer
The run view includes an inline artifact viewer that renders artifact contents directly in the browser. The viewer activates automatically based on the artifact's content type:
| Format | Display |
|---|---|
| Text / plain text | Syntax-highlighted code viewer |
| JSON | Collapsible tree view for objects and arrays |
| CSV / TSV | Scrollable table with column headers |
| Apache Parquet | Rendered as a scrollable table |
| Images (PNG, JPEG, GIF, WebP, etc.) | Displayed inline |
Click the fullscreen button to expand the viewer to fill the screen. For artifact types that cannot be rendered inline, a download link is shown instead.
Tabular viewer (CSV, TSV, Parquet)
Tabular artifacts share a common viewer with paging and sticky headers:
- Initial load: the first 100 rows are rendered. The footer shows "Showing first 100 rows".
- Load more: click Load more to append another 100 rows. The viewer continues paging up to a 1,000-row preview limit, after which the footer changes to "Showing first 1000 rows (preview limit reached)".
- Load all: click Load all to jump straight to the preview limit without paging.
- Sticky column headers: headers remain visible while you scroll the table vertically. The table also scrolls horizontally when columns overflow the viewport.
- Column types: when the artifact's schema is available (such as for Parquet files), each column header shows the column type below the name. Nullable columns are marked with a trailing
?(for exampleint64?).
Use the standalone artifact preview page (below) when you need to share a view of an artifact or browse it on its own dedicated page — the tabular viewer there behaves the same way but uses the full window height.
Standalone artifact preview page
Every artifact has a dedicated, shareable preview page at /artifact/<artifact-id>. The page renders the same inline viewer as the run view but fills the browser window, which is useful for inspecting large tables or sharing a specific artifact with a collaborator.
There are two ways to open the page from the run view:
- Cmd/Ctrl + click the fullscreen button in the artifact visualizer dialog. The standalone page opens in a new browser tab.
- Click the Share button in the artifact visualizer header. The full preview URL is copied to your clipboard and a "Link copied to clipboard" toast confirms the copy. Paste the link to share it with another user, or open it later.
The preview URL accepts optional type and name query parameters so the page can pick the right viewer and display label without round-tripping to the run view. Anyone with access to the same TangleML backend can open the link; if the artifact has aged out of remote storage, the page shows the same Artifact unavailable notice described above.